
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- MaskRCNN코랩
- 다중 회귀
- 기사단원의무기
- spleeter
- rogistic regression
- 객체 성능 평가 지표
- MaskRCNN_colab
- stratified k-fold
- PyQt5
- bcss
- 피처 스케일링
- 청산원함
- 엘라스틱넷
- mmdetection
- MaskRCNN환경구성
- seaborn.barplot
- flask모델서빙
- docker
- mask2coco
- bargraph
- 로지스틱 회귀
- mask2cocojson
- 프로그래머스
- MaskRCNN환경구축
- RMSLE
- 모델 성능 최적화
- Python
- 회귀 평가 지표
- stacking
- MSLE
- Today
- Total
노트와 노트
거대 언어 모델(Large Language Models, LLMs)의 할루시네이션 문제 완화(방지) 방안 본문
거대 언어 모델(Large Language Models, LLMs)의 할루시네이션 문제 완화(방지) 방안
gellygelly 2024. 4. 30. 23:12최근 하루가 멀다하고 고성능의 LLM이 쏟아져 나오는 세상에서, 계속해서 대형 언어 모델의 한계점으로 제기되고 있는 문제가 있다. 바로 ‘Hallucination(환각)’ 문제이다.
이번 포스팅에서는 할루시네이션이 무엇이고 주요 발생 원인은 무엇인지, 그리고 할루시네이션 완화를 위한 방안에는 어떤 것이 있고 실제 완화 방안을 도입한 사례까지 정리하려고 한다.
LLM의 Hallucination(환각)이란?
AI 분야에서의 환각은 ‘마치 환각을 보는 듯이, 거대 언어 모델이 사실이 아닌 내용을 진실인 양 자연스럽게 대답하는 현상’을 일컫는다.
- 답변이 없을 때 허위 정보를 제공 (가장 대표적)
- 사용자가 구체적이고 최신의 응답을 기대할 때 오래되었거나 일반적인 정보를 제공
- 신뢰할 수 없는 출처로부터 응답을 생성
- 용어 혼동으로 인해 응답이 정확하지 않음. 다양한 훈련 소스가 동일한 용어를 사용하여 서로 다른 내용을 설명
(출처: https://aws.amazon.com/ko/what-is/retrieval-augmented-generation/)
Chat GPT(3.5)에게 아래와 같은 질문을 던졌을 때, 사실이 아닌 정보를 마치 사실인 것처럼 줄줄 대답하는 것을 볼 수 있다.
(예시) 태조 이성계가 즐겨먹었던 뚱카롱이요? … 😫

Hallucination 주요 발생 원인
그렇다면 이러한 할루시네이션 현상은 왜 발생할까?
흔히 사람들이 생각하는 것처럼 언어 모델이 마치 사람처럼 터득한 지식(학습 데이터셋)에 대해 온전히 ‘이해’하고 이를 바탕으로 ‘추론’하는 것이 아니기 때문이다.
LLMs은 거대한 양의 학습 데이터셋을 바탕으로 학습을 진행하며 학습 과정에서 단어 간의 관계성, 패턴, 확률을 파악하게 된다.
이러한 학습 과정을 토대로, 주어진 문장을 기반으로 첫 단어부터 순서대로 이어질 단어를 예측(추론)하게 되는데, 예를 들어 ‘집에’ 라는 단어가 주어졌을 때 다음 단어로 어떤 단어가 나올 확률이 제일 높은지에 대해 예측하여 최종적으로 사용자에게 완성된 문장을 출력해주는 것이다.
본질적으로, 이러한 생성형 AI의 주요 목적은 사실에 기반한 정확한 정보를 전달하는 것이 아닌, 자연스러운 ‘문장을 생성’하는 데에 있기 때문이다.
추가로 할루시네이션이 발생하는 주요 원인을 정리해보자면 다음과 같다.
1. 학습 데이터의 품질
원본 데이터에 부정확하고 편향된 정보가 있다면 이를 그대로 학습한 LLMs은 이러한 부정확한 정보를 기반으로 대답을 생성할 수밖에 없다.
(예: 정보의 출처가 불분명한 해외 커뮤니티 Reddit을 학습 데이터에 포함시킨 Chat GPT)
2. 언어 자체의 복잡성
같은 단어여도 문맥에 따라 다른 의미로 받아들여질 수 있는데, LLMs은 사람처럼 문맥을 제대로 이해하고 이를 기반으로 문장을 출력하는 것이 아니기 때문에 문맥을 제대로 파악하지 못하고 엉뚱한 방향으로 생성하는 경우가 생긴다.
3. 프롬프트 오류
사용자가 명확하지 않고 모순된 프롬프트를 입력할 경우에도 할루시네이션이 발생한다. 이런 경우, 프롬프트를 명확하게 수정해주면 되므로 이는 다른 방법에 비해 비교적 간단한 문제이다.
Hallucination 방지 방안 및 사례
단순히 LLM을 끝말잇기와 같은 시간 때우기용(ㅋㅋ)이나 호기심 목적으로 사용한다면 상관이 없지만, 기업이나 각종 기관에서 LLM을 비즈니스적으로 도입하고자 할 때 할루시네이션 문제는 기업의 신뢰성과 직결되는 위험한 문제가 되기 때문에 주의해야 한다. 또한 LLM이 생성한 거짓 정보가 마치 사실인 것처럼 퍼져나가 유해한 결과를 초래할 수 있으므로 환각 현상을 개선하기 위해 노력해야 한다.
라는 것은 알겠는데, 그래서 어떻게! 환각 문제를 완화할 수 있을까? 해서 찾아보았다.
1. RAG(Retrieval-Augmented Generation, 검색 증강 생성) 기술
각종 기업들의 LLM 환각 방지 방안을 조사해보니, 가장 흔하게 쓰이고 있고 국내 여러 기업에서도 도입한 기술이다.
RAG(Retrieval-Augmented Generation; 검색 증강 생성) 기술은 LLM이 답변을 생성하기 전에 외부 데이터베이스에서 질문과 관련된 정보를 검색하는 과정으로 할루시네이션 방지에 효과적인 것이 특징이다.
즉, ‘출처(사실)’에 기반한 답변을 생성하는 방식이다.
아래 이미지를 보면 알 수 있듯이 답변을 생성하기 앞서 방대한 Knowledge Sources(외부 지식 소스)에서 관련 정보를 검색하여 답변을 생성하는 것을 알 수 있다.
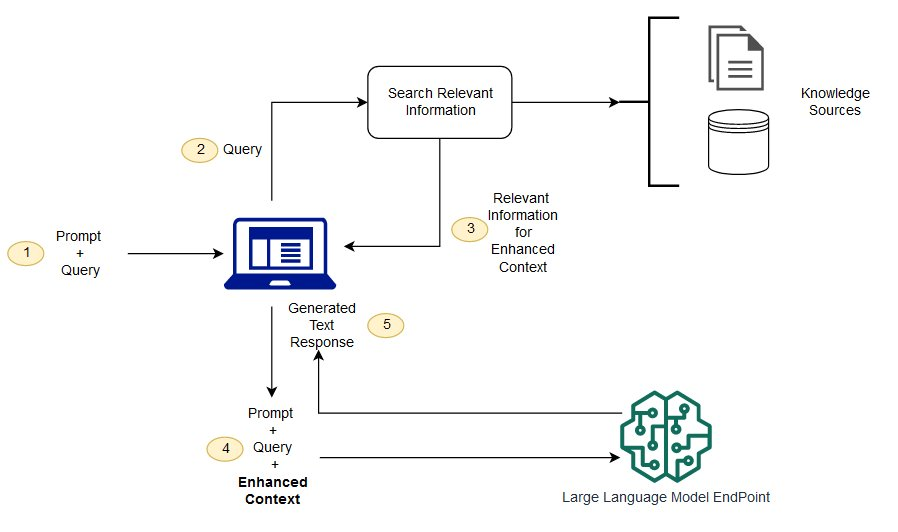
(참고) 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황
아래 링크에 RAG란 무엇인지, RAG 기술 현황에 대해 너무 잘 정리되어 있다~!! 👍🏻 👍🏻 👍🏻 👍🏻 👍🏻
https://www.gnict.org/blog/130/글/대규모-언어-모델을-위한-검색-증강-생성rag-기술-현황/
대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 - (사)경남ICT협회
(아래 내용은 파이 토치 유저 모임에서 가져온 내용입니다) 검색-증강 생성(RAG) 기술 소개 RAG 기술의 발전 - 타임라인 / A timeline of existing RAG research1376×919 159 KB 대규모 언어 모델(LLM)은 뛰어난
www.gnict.org
- 할루시네이션 완화를 위해 RAG를 도입한 국내 사례
✅ Bella QNA(벨라 큐나) - 스켈터랩스가 개발한 GPT 기반의 Q&AI 서비스
KB 국민카드의 이벤트 Q&AI 서비스에 도입된 Bella QNA는 RAG를 활용해 매일 변화하는 최신 이벤트 정보를 간편하게 업데이트하고 이를 기반으로 답변을 생성.

✅ 로앤봇 - 로앤굿이 개발한 자연어 검색이 가능한 변호사용 인공지능 챗봇
로앤봇은 개인정보 포털에 공개된 최근 5년간 총 4360페이지에 달하는 결정문·심결례·가이드라인·판례집 등을 학습했으며 RAG를 활용해 국내법에 특화된 챗봇으로 구현.
※관련 링크:
https://www.legalaicorp.com/ (로앤굿 홈페이지)
https://legalgpt-traffic.lawandgood.com/ (로앤봇 이용 페이지)
✅ 빅케이스 GPT - 로톡 운영사 로앤컴퍼니와 AI 기반 통합 법률정보 서비스인 빅케이스가 만든 AI 기반 통합 법률정보 서비스
빅케이스 GPT에 GPT-4를 기반으로 RAG 모델과 자체 고안한 프롬프트 엔지니어링 적용
빅케이스가 확보하고 있는 국내 최다 판례 329만건 중 정보 가치가 높은 판례를 중심으로 벡터화된 데이터베이스를 구축함으로써 법률 분야 질의에 최적화된 답변을 내놓도록 설계
빅케이스GPT에 판례뿐 아니라 빅케이스가 보유한 법령 14만5000건, 결정례 7000건, 유권해석 7000건 등 총 16만건의 법률정보도 추가로 학습
※ 출처 : AI타임스(https://www.aitimes.com)
✅ Solar model - 업스테이지가 개발한 LLM
RAG와 Answer Verification 방법을 같이 적용하여 응답의 정확성을 보장한 LLM
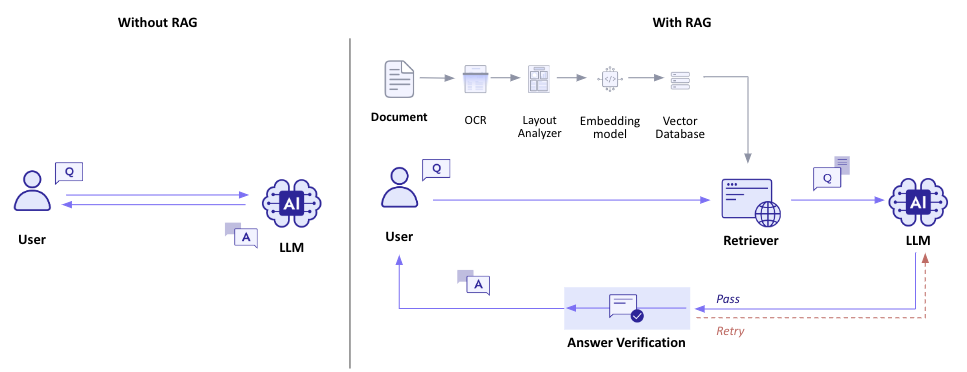
이전에 Ko-LLM-Leaderboard에서 업스테이지의 solar를 기반으로 한 모델들이 줄줄이 상위권에 있는 것을 본 듯 한데 지금도 여전한 듯 하다.
찾아보니 성능 관련 기사는 2023.12월자인데 (※출처: https://www.aitimes.com/news/articleView.html?idxno=156173) 현재 ko-llm-leaderboard(https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard) 봐도 아직도 상위권이다.
(참고) RAG 성능을 향상시키기 위한 Raranking(순위 재정렬) 활용
※ 출처: https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/ (AWS 기술 블로그, Dongjin Jang, Ph.D.)
- RAG의 문제점
RAG 시스템이 실제 애플리케이션에 적용될 때, 기본적인 파이프라인 구성 만으로는 프로덕션 수준의 높은 요구사항을 충족하기 어렵기 때문에 추가적인 개선 방안 필요
- 구체적인 예
RAG를 사용하면 일반적으로 연관 문서를 k개 가져와서 사용하게 되는데, 이러한 후보 문서들 중 k+1이후의 데이터에만 정답이 들어 있다면? → RAG를 적용하더라도 여전히 할루시네이션 문제 발생
단순히 k를 늘리는 방법으로만 처리한다면? → 모델의 메모리 사용량 및 답변 생성 속도가 느려짐. 또한 최근 연구에 따르면, RAG의 정확도는 관련 정보의 컨텍스트 내 존재 유무보다는 순서에 더 영향을 받는다는 것이 발견됨(관련 정보가 상위권에 존재할 때 좋은 답변을 얻을 수 있다는 의미, Lost in the Middle: How Language Models Use Long Contexts, F.Liu et al., 2023)
- Reranking이란?
Reranking은 이러한 개선 방안 중 하나로 RAG가 생성한 후보 문서들에 대해 질문에 대한 관련성 및 일관성을 판단하여 문서의 우선 순위를 재정렬 하는 것
아래와 같이 two-stage 전략을 적용하여 RAG를 적용한 LLM의 성능을 향상시킬 수 있음.
- 기존의 벡터 검색 방식(RAG)으로 대규모 문서 중 질문과 관련성이 높은 후보군 선정
- 검색된 문서들에 대해 reranker 기반으로 관련성을 재측정
- 1, 2 과정을 기반으로 답변 생성
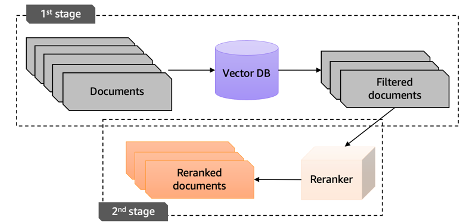
이러한 rerank 기법은 이미 LlamaIndex, LangChain, HayStack 등과 같은 LLM 어플리케이션 프레임워크에 구현되어 있다. 위의 출처 링크에서는 LangChain을 통해 구현했다.
이 외에도 RAG의 성능을 향상시키기 위한 여러 방법들이 있는데, 위의 <(참고) 대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황(https://www.gnict.org/blog/130/글/대규모-언어-모델을-위한-검색-증강-생성rag-기술-현황/)> 부분 링크에 잘 설명되어 있어 Rerank 말고도 다른 방법들도 한 번 살펴보면 좋을 것 같다.
2. 프롬프트 엔지니어링
RAG 시스템을 도입하는 것 외에도 프롬프트 수정만으로도 간단하게 환각 현상을 일부 완화할 수도 있다. 이 방법은 자체 외부 데이터베이스를 구축하는 데 필요한 시간 및 비용이 들지 않고 즉각적으로 환각을 약간 완화할 수 있으므로 시간적 비용적 측면에서 다소 효율적이다.
✅ CoT(Chain of Thought) Prompting / papers: https://arxiv.org/abs/2201.11903
프롬프트에 “단계별 생각”을 추가하는 작업. 작업을 단계적으로 나누어 답을 도출하기 위한 중간 추론 단계를 설명하도록 하여 추론 능력을 향상시킴으로써 답변의 품질을 향상시키는 방법.
특히 수학적 문제나 논리적 문제에 적합한 방법이다.

- Zero-shot CoT Prompting
‘Large Language Models are Zero-Shot Reasoners’ 논문(https://arxiv.org/abs/2205.11916)에서는, 별도의 조정이나 중간 추론 단계의 예시를 제공하지 않아도 단지 ‘단계적으로 생각해 봅시다’ 라고 말하는 것만으로도 할루시네이션 개선 효과가 나타났다고 한다.

✅ Self consistency with CoT(CoT-SC) (papers: https://arxiv.org/abs/2203.11171)
CoT와 같이 단계적으로 생각하되, 모델에게 몇 가지 답변을 제공한 후 투표를 통해 가장 좋은 답변을 선택하도록 요청하는 방법.
(예시 프롬프트)
Think step by step before answering and give three answers: if a domain expert were to answer, if a supervisor were to answer, and your answer. Here’s the response in JSON format:
✅ Tree of Thoughts(ToT) (papers: https://arxiv.org/abs/2305.10601)
LLM에게 CoT 접근 방식을 일반화하고 다음 역할을 하는 일관된 텍스트(생각)에 대한 탐색을 할 수 있도록 장려하는 방법. 이를 통해 LLM은 의도적인 추론 과정을 통하여 문제 해결을 위한 중간 생각의 진행 상황을 자체 평가할 수 있음.
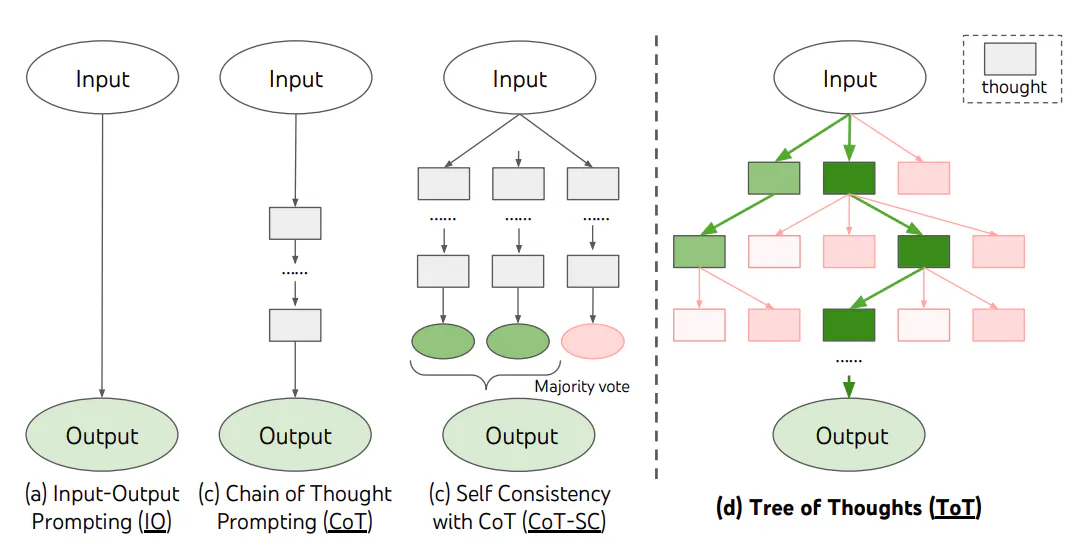
(예시 프롬프트)
Imagine three different experts are answering this question. All experts will write down 1 step of their thinking, then share it with the group. Then all experts will go on to the next step, etc. If any expert realises they’re wrong at any point then they leave. Here’s the response in JSON format:
✅ Tagged Context Promtpts (papers: https://arxiv.org/pdf/2306.06085.pdf)
LLM이 외부 도메인 지식을 활용할 때, 사용자에게 정확한 정보를 받을 수 있도록 보장하기 위해 데이터 소스와 해당 출처를 제공하도록 하는 방식

(예시 프롬프트) Provide details and include sources in the answer. Return response in JSON format, for example: [{“class”: “A”, “details”: “Human blood in veins is not actually blue. Blood is red due to the presence of hemoglobin”, “source”: “https://example.com"}]
✅ Self-Correct (papers: https://arxiv.org/abs/2305.11738)
사람이 외부 툴(검색 엔진, 코드 인터프리터 등)을 이용하여 본인의 초기 콘텐츠를 교차 검증하고 체크하듯이, LLM이 결과를 다시 확인하고 스스로 수정하도록 하는 방법.
아래는 CRITIC framework의 간단한 컨셉이다.

✅ Several Agents (papers: https://arxiv.org/abs/2305.14325)
모델 앙상블과 같이 여러 라운드에 걸쳐 개별 응답 및 추론 프로세스를 제안하고 토론하는 방법.
다만 이 방법에는 여러 모델을 사용해야 하기 때문에 응답에 걸리는 시간이 훨씬 길 뿐만 아니라 API 비용 증가 측면에서도 문제가 있어 실제 애플리케이션에 적용하는 것은 추천하지 않음.
[기타 자료]
- LLM Hallucination Leaderboard (모델별 Hallucination Rate, Factual Consistency Rate 등 제공)
https://github.com/vectara/hallucination-leaderboard?tab=readme-ov-file
- LLM 할루시네이션 관련 연구 모음 👍🏻
https://github.com/HillZhang1999/llm-hallucination-survey
[ 📌참고한 글]
https://www.skelterlabs.com/blog/bellaqna-rag-hallucination
https://blog.kakaocloud.com/61
https://betterprogramming.pub/fixing-hallucinations-in-llms-9ff0fd438e33
'Machine Learning & DeepLearning' 카테고리의 다른 글
| Convert multiclass mask image to coco json 작업 + TypeError: Argument 'bb' has incorrect type (expected numpy.ndarray, got list) 에러 해결 (1) | 2024.04.25 |
|---|---|
| 음원 분리를 위한 Spleeter 모델 구축: 환경 구성, 학습 및 테스트 방법 (1) | 2023.10.18 |
| GAN(Generative Adversarial Networks)이란? (0) | 2023.09.26 |
| 모델 성능 최적화 방법들 (0) | 2023.09.18 |
| 머신러닝 회귀(Regression) (0) | 2022.05.02 |


