
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 모델 성능 최적화
- bargraph
- MaskRCNN환경구축
- 회귀 평가 지표
- 엘라스틱넷
- 기사단원의무기
- MSLE
- 로지스틱 회귀
- 객체 성능 평가 지표
- 청산원함
- MaskRCNN환경구성
- 피처 스케일링
- stratified k-fold
- rogistic regression
- PyQt5
- MaskRCNN코랩
- mmdetection
- 프로그래머스
- seaborn.barplot
- MaskRCNN_colab
- mask2cocojson
- spleeter
- flask모델서빙
- Python
- stacking
- 다중 회귀
- docker
- bcss
- mask2coco
- RMSLE
- Today
- Total
노트와 노트
머신러닝 분류(Classification) (2) - 앙상블(Ensemble) 기법 본문
머신러닝 분류(Classification) (2) - 앙상블(Ensemble) 기법
gellygelly 2022. 5. 1. 19:14※ 이 글은 <파이썬 머신러닝 완벽 가이드(위키북스, 권철민 저)> 책 공부한 내용&개인적으로 공부한 내용을 정리한 글입니다.
앙상블 학습(Ensemble Learning)
여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법. 이미지, 영상, 음성 등의 비정형 데이터의 분류는 딥러닝이 뛰어난 성능을 보이고 있으나, 대부분의 정형 데이터 분류 시에는 앙상블이 뛰어난 성능을 나타내고 있음.
앙상블 학습의 유형
- 보팅(Voting)
- 배깅(Bagging)
- 부스팅(Boosting)
- 스태킹(Stacking)
보팅(Voting)
서로 다른 알고리즘을 가진 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식.

- 보팅 유형
① 하드 보팅(Hard Voting): 다수결. 예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정.
② 소프트 보팅(Soft Voting): 평균값. 각 분류기들의 레이블 결정 확률을 모두 더하고 평균값 구해서 확률이 제일 높은 레이블 값을 최종 보팅 결과값으로 결정.
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
# 개별 모델 - 로지스틱 회귀, KNN
lr = LogisticRegression()
knn = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
voting = VotingClassifier(estimators=[('LR', lr), ('KNN', knn)], voting='soft') # voting = soft or hard (default는 hard)
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=156)
# VotingClassifier 학습/예측/평가
voting.fit(X_train, y_train)
pred = voting.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test, pred)))
# 개별 모델의 학습/예측/평가
classifiers = [lr, knn]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print('{0} 정확도: {1.4f}'.format(class_name, accuracy_score(y_test, pred)))
배깅(Bagging)
서로 같은 알고리즘을 가진 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식. 분류기의 알고리즘 유형은 모두 같지만, 데이터 샘플링을 서로 다르게 가져가면서 학습 후 보팅을 수행함.

랜덤 포레스트(Random Forest)

랜덤 포레스트는 배깅의 대표적인 알고리즘으로, 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 하는 알고리즘이다.
랜덤 포레스트의 개별 분류기의 기반 알고리즘은 결정 트리이지만, 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트이다. 이러한 데이터 샘플링 방식을 '부트스트래핑(Bootstrapping) 분할 방식'이라고 한다.
부트스트래핑(Bootstrapping) 분할 방식
서브 세트의 데이터 건수는 전체 데이터 건수와 동일하지만, 중첩된 개별 데이터로 구성되어 있음.

from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset()를 이용해 학습/테스트용 DataFrame 반환
# 랜덤 포레스트 학습 및 별도의 테스트 세트로 예측 성능 평가
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('랜덤 포레스트 정확도: {0:4f}'.format(accuracy))
※ 트리 기반의 앙상블 알고리즘의 단점
- 하이퍼 파라미터가 너무 많고, 그로 인해서 튜닝을 위한 시간이 많이 소모됨
- 많은 시간을 소모하여 튜닝을 수행해도 튜닝 후 예측 성능이 크게 향상되는 경우가 많지 않음
부스팅(Boosting)
여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에게는 가중치(weight)를 부여하며 학습과 예측을 진행하는 방식.

에이다부스트(AdaBoost)
에이다부스트는 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘이다.

위와 같이, +와 -로 구성된 피처 데이터 세트가 있을 때, 다음과 같이 학습을 수행한다.
① [step 1] 첫 번째 약한 학습기(weak laerner)가 분류 기준 1로 데이터셋을 분류한다. 이 중 동그라미 표시된 데이터는 잘못 분류된 데이터이다.
② [step 2] 잘못 분류된 데이터에 가중치를 부여한다.
③ [step 3] 두 번째 약한 학습기가 분류 기준 2로 데이터셋을 분류한다. 이 중 동그라미 표시된 데이터는 잘못 분류된 데이터이다.
④ [step 4] 잘못 분류된 데이터에 가중치를 부여한다.
⑤ [step 5] 세 번째 약한 학습기가 분류 기준 3으로 데이터셋을 분류한다.
⑥ 최종적으로 학습기를 모두 결합하여 예측을 수행한다.
이 과정을 수식으로 나타내면 다음과 같다.
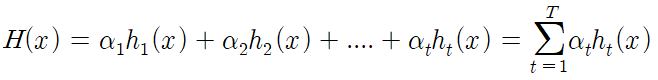
- H(x): 최종 분류기(여러 학습기를 모두 결합한 분류기)
- α: 각 약한 분류기(학습기)의 가중치
- h(x): 각 약한 분류기(학습기)
- T: 약한 분류기(학습기)의 개수
GBM(Graient Boost Machine)
GBM은 에이다부스트와 유사하지만 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이이다. 경사 하강법이란, 반복 수행을 통해 오류를 최소화할 수 있도록 가중치의 업데이트 값을 도출하는 기법이다.

GBM은 우선 간단한 모델 tree 1로 예측을 수행하고, 모델의 예측 결과값(y)과 실제 값(Ground Truth) 사이의 잔여 오차(Residual Error; 잔차)를 이용해서 다음 모델 tree 2를 학습시킨다. 그 다음에는 tree 2의 잔차를 이용해 tree 3를 학습시킴으로써 갈수록 잔차를 줄여갈 수 있도록 순차적으로 학습을 진행하는 방법이다.
GBM은 일반적으로 랜덤 포레스트보다는 예측 성능이 뛰어난 경우가 많으나 수행 시간이 오래 걸린다는 단점이 있다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
import time
X_train, X_test, y_train, y_test = dataset() # dataset 지정
gbm = GradientBoostingClassifier()
gbm.fit(X_train, y_train)
pred = gbm.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('GBM accuracy: {0:.4f}'.format(accuracy)
XGBoost(eXtra Gradient Boost)
XGBoost는 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나로, 분류에 있어서 일반적으로 다른 머신러닝 기법에 비해 뛰어난 예측 성능을 보인다.
XGBoost는 GBM에 기반하고 있으나 GBM의 단점인 느린 수행 시간 및 과적합 규제(Regularization) 부재 등의 문제를 해결해서 매우 각광받고 있다.
<XGBoost의 주요 특징>
- 뛰어난 예측 성능
- GBM 대비 빠른 수행 시간
- 과적합 규제 - 과적합에 좀 더 강한 내구성 가짐
- Tree pruning(나무 가지치기) - 더 이상 긍정적인 이득이 없는 분할을 가지치기하여 분할 수를 더 줄임(max_depth로 분할 깊이 조정도 가능)
- 자체 내장된 교차 검증 - early stopping 가능
- 결손값 자체 처리
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
xgb = XGBClassifier(n_estimator=400, learning_late=0.1, max_depth=3)
# n_estimator: weak learner 개수
# learning_late: 학습률
# max_depth: 트리 기반 알고리즘의 max_depth와 동일 / 일반적으로 3-10 지정/ max_depth가 크면 특정 피처 조건에 특화되어 조건 생성 -> 과적합 가능성 높아짐
xgb.fit(X_train, y_train)
pred = xgb.predict(X_test)
pred_proba = xgb.predict_proba(X_test)[:, 1]LightGBM(Light Gradient Boost Machine)
LightGBM은 XGBoost에 비해 뒤지지 않는 성능을 가지고 있으면서, 학습에 걸리는 시간은 훨씬 적게 걸리는 알고리즘이다.
LightGBM은 일반 GBM 계열의 트리 분할 방식과 다르게 리프 중심 트리 분할(Leaf wise) 방식을 사용한다. 리프 중심 트리 분할 방식은 트리의 균형을 맞추지 않고, 최대 손실 값(max delta loss)을 가지는 리프 노드를 지속적으로 분할하면서 비대칭적 트리를 생성하여, 예측 오류 손실을 최소화하는 방식이다.

<LightGBM의 장점>
- 더 빠른 학습 및 예측 수행 시간
- 더 적은 메모리 사용량
- 카테고리형 피처의 자동 변환과 최적 분할(원-핫 인코딩 등을 사용하지 않고도 카테고리형 피처를 최적으로 변환하고 이에 따른 노드 분할 수행)
<LightGBM의 단점>
- 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉬움 (일반적으로 10,000건 이하 - 공식 문서에서 기술)
from lightgbm import LGBMClassifier
from sklearn.metrics import roc_auc_score
lgbm = LGBMClassifier(n_estimators=500)
evals = [(X_test, y_test)]
lgbm.fit(X_train, y_train, early_stopping_rounds=100, eval_metric='auc', eval_set=evals, verbose=True)
roc_score = roc_auc_score(y_test, lgbm.predict_proba(X_test)[:, 1], average='macro')
print('ROC AUC: {0:.4f}'.format(roc_score)스태킹(Stacking)
스태킹 앙상블은 스택(Stack)이라는 단어처럼, 여러 가지 모델을 쌓아 학습 및 예측을 진행하는 방법으로, 개별 알고리즘의 예측 결과 데이터 세트를 최종적인 메타 데이터 세트로 만들어 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 다시 최종 예측을 수행한다.

책에서는 스태킹을 현실 모델에 적용하는 경우는 그리 많지 않고, 캐글과 같은 대회에서 높은 순위를 차지하기 위해 조금이라도 성능 수치를 높여야 할 경우 많이 사용된다고 소개하고 있다.
스태킹을 적용할 때는 많은 개별 모델이 필요하며, 2-3개의 개별 모델을 적용해서는 쉽게 예측 성능 성능을 향상할 수 없으며 스태킹을 적용한다고 해서 반드시 성능 향상이 되리라는 보장도 없다고 한다.
개별 스태킹 모델은 일반적으로 최적으로 파라미터를 튜닝한 상태에서 스태킹 모델을 생성한다. 아래 코드는 파라미터 튜닝이 끝났다고 가정하고 개별 모델과 해당 모델의 예측 결과를 바탕으로 최종 메타 모델을 생성하는 코드이다. (책 280-282p)
# 기본 스태킹 모델을 위스콘신 암 데이터 세트에 적용
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_data = cancer_data.target
# dataset
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.2)
# 개별 ML 모델 생성
knn = KNeighborsClassifier(n_neighbors=4)
rf = RandomForestClassifier(n_estimators=100)
dt = DecisionTreeClassifier()
ada = AdaBoostClassifier(n_estimators=100)
# 스태킹으로 만들어진 데이터 세트를 학습, 예측할 최종 모델
lr = LogisticRegression(C=10)
# 개별 모델들을 학습
knn.fit(X_train, y_train)
rf.fit(X_train, y_train)
dt.fit(X_train, y_train)
ada.fit(X_train, y_train)
# 개별 모델들 예측
knn_pred = knn.predict(X_test)
rf_pred = rf.predict(X_test)
dt_pred = dt.predict(X_test)
ada_pred = ada.predict(X_test)
print('KNN accuracy: {0:.4f}'.format(accuracy_score(y_test, knn_pred)))
print('RandomForest accuracy: {0:.4f}'.format(accuracy_score(y_test, rf_pred)))
print('DecisionTree accuracy: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
print('AdaBoost accuracy: {0:.4f}'.format(accuracy_score(y_test, ada_pred)))
## 개별 알고리즘의 예측값을 칼럼 레벨로 옆으로 붙여서 피처 값으로 생성
## 생성한 피처 값은 최종 모델의 학습 데이터로 이용
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
print(pred.shape)
pred = np.transpose(pred) # 행 열 위치 교환
print(pred.shape)
# 최종 모델 학습 및 예측
lr.fit(pred, y_test)
final = lr.predict(pred)
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test, final)))


