GAN(Generative Adversarial Networks)이란?
1. GAN(Generative Adversarial Networks)이란?
GAN은 Generative Adversarial Networks의 약자로 우리말로는 '적대적 생성 신경망'이라고 한다. GAN은 Generative AI의 한 종류로 사람이 쓴 것 같은 글, 사진 등 실제에 가까운 가짜 데이터들을 생성하는 모델이며, '적대적 생성' 이라는 이름에서 알 수 있듯 서로 다른 두 개의 네트워크를 적대적으로(Adversarial) 학습시키며 실제와 비슷한 데이터를 생성(Generative)한다.
2. 개념(Concept)과 구조(Architecture)
GAN은 확률 분포를 학습하며 끊임없이 실제에 가까운 거짓 데이터를 생성하는 Generator(이하 G)와 데이터가 Generator에 의해 생성된 것인지, 아니면 실제 데이터인지를 구별하는 Discriminator(이하 D)로 구성되어 있다. 두 모델은 적대적 프로세스로
GAN의 궁극적 목표는 실제 데이터의 분포에 근사한 데이터를 생성해내는 것이며, D가 진짜인지 가짜인지를 판별하지 못하는 수준에 이르렀을 때 (주어진 표본을 실제 표본이라고 판단할 확률이 0.5에 이르렀을 때) 최적의 상태에 이르렀다고 판단한다.
GAN의 제안자 Lan Goodfellow는 '경찰과 위조지폐범'을 예시로 들어 GAN의 개념을 설명하고 있는데 아래와 같다.

1) random Noise z를 이용해서 G(위조지폐범)가 위조 지폐 G(z)를 생성한다.
2) D(경찰)은 G가 만든 위조 지폐(G(z))와 Real Money가 Fake인지 Real인지 판단한다. (예: 위조지폐(G(z)) = 0, x: 1)
3) 1~2의 과정을 거치면 한 Epoch가 끝나고, 이후 Epoch에서도 1~2의 과정을 계속해서 거치며 G는 D가 Fake인지 Real인지 구분할 수 없도록 Real Money에 가까운 데이터들을 생성하는 방향으로 고도화해나간다.
4) 어느 순간 D가 Fake Data와 Real Data를 구분하지 못하는 순간이 오면 (50%) 학습이 종료된다.

3. GAN Models

1. Unconditional GAN
StyleGAN
2019년 CVPR에 발표된 'A Style-Based Generator Architecture for Generative Adversarial Networks'라는 논문에서 제안된 모델로, 흔히 StyleGAN이라 불리며 인간의 얼굴에 관한 특징을 외워 현실에 존재하지 않는 새로운 인간의 이미지를 생성하는 모델이다. StyleGAN의 특징 중 하나는 Localization으로 style의 특정 subset을 변경하는 게 아니라 이미지의 특정 부분을 변경하는 데에 효과를 낸다. 아래 사진을 보면, SourceA를 기반으로 SourceB의 특정 특징이 적용된 결과 이미지를 볼 수 있다.

2. cGAN(Conditional Generative Adversarial Networks)
cGAN(Conditional Generative Adversarial Networks)의 종류 중 하나로, cGAN은 GAN과는 달리 G와 D가 훈련하는 동안 추가 정보(label)를 이용하여 훈련하는 GAN이다. GAN과는 달리 1) 샘플링 시 어떤 방법을 사용하는지 2) 데이터셋의 라벨 유무 측면에서 차이가 있다.
| GAN | cGAN | |
| 샘플링 방법 | Random 클래스 중에서 샘플 뽑음 | 원하는 클래스 중 샘플 뽑음 |
| 라벨링 데이터 필요 유무 | 필요X | 필요O |
Pix2Pix
'Image-to-Image Translation with Conditional Adversarial Networks' 논문에서 제안된 모델로, random noise z가 아닌 이미지를 input으로 받아 다른 style의 이미지를 output으로 출력하는 image-to-image translation을 수행하는 모델이다. 타 GAN 모델들과는 달리 스케치 그림을 입력하여 실제 사진처럼 변환하는 작업을 수행한다.

CycleGAN
'Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks' 에서 제안된 모델로 다양한 스타일 간 이미지 간 변환을 학습하는 데에 주로 사용된다. 아래와 같이 얼룩말과 말 사이의 변환, 모네 화풍 그림과 사진 간 변환 등의 이미지 변환이 가능하다.

StarGANv2
NaverClova가 발표한 'StarGAN v2: Diverse Image Synthesis for Multiple Domains' 라는 논문에서 제안된 모델이다.
StarGAN은 기존 GAN의 경우 단일 모델로는 단일 도메인 이미지 변환기밖에 만들 수 없어 여러 도메인에 대한 변환을 수행하려면 변경하고자 하는 도메인 갯수만큼의 모델이 필요했다면, 하나의 모델로 여러 도메인의 이미지를 생성할 수 있도록 제안된 모델이다.
StarGANv2는 각각의 도메인에 대해 동일한 변형만 가능했던 StarGAN에서 더 나아가 domain-specific style code로 변경하며 이미지 생성 뿐만 아니라 image-to-image translation도 가능하며 단일 스타일 인코더, 단일 생성기를 사용하여 다양한 도메인에 대한 style transfer가 가능하다.

5. 평가 지표(Evaluation Metrics)
GAN의 창시자 lan Goodfellow가 GAN에 대해 소개한 이후, 한동안 GAN은 일반적으로 모델 간 퍼포먼스를 증명하기 위해 널리 쓰이는(분류 모델의 Accuracy나 회귀 모델의 MSE 등) 평가 지표가 없어 GAN의 활용성을 증명하기가 어려웠다.
이후 다양한 평가 지표들이 제안되었으나 2018년 Ali Borji는 GAN의 평가 지표 간의 장단점을 기술한 논문에서 'GAN 모델의 강점과 한계점을 반영하는 가장 적절한 지표에 대해서는 아직도 의견 일치가 이루어지지 않았다'고 언급했다.
사실상, 이전에 프로젝트를 할 때도 어떠한 정량적인 평가 지표를 적용하기보다는 생성 대상의 도메인 문맥에 따라 생성된 이미지의 퀄리티를 대략적으로 평가하는 방식을 이용했었는데, 사실 사람이 이미지를 평가하는 방식은 시간과 비용이 많이 드므로 그다지 좋은 방법은 아니다. 따라서, 아래에서는 비교적 논문들에서 모델 비교 시 자주 쓰였던 정량적 평가 지표 2가지에 대해 소개한다.
IS (Inception Score)
클래스 label과 관련하여 특징적인 속성을 잡아내기 위해 inception model을 사용하는 지표이다. inception model(https://arxiv.org/pdf/1512.00567.pdf)은 1000개의 클래스와 120만개의 이미지로 구성된 ImageNet 훈련 데이터를 pre-trained한 CNN 모델로, 이미지가 입력되면 1000개의 클래스 중 해당 이미지가 각 1000개의 클래스에 속할 확률 vector를 출력한다.

샘플의 조건부 분포 p(y|x)와 모든 샘플에서 얻은 주변분포 p(y) 사이의 평균적인 KL 발산 정도(Average KL Divergence)를 측정하며 갚이 높을수록 좋은 성능을 내는 모델이다.
- conditional label distribution p(y|x) : 생성된 image의 품질을 측정하는 부분으로, 생성된 image x를 inception 모델을 통해 나온 각 label에 대한 확률 분포를 의미. 이상적인 conditional label distribution 특정 label이 높게 나온 분포이다.
- Marginal distribution p(y) : 생성된 image의 다양성을 측정하는 부분으로, 여러 개의 생성된 이미지들을 이용하여 label의 분포를 합산한 새로운 분포를 의미. 이상적인 Marginal distribution은 균등한 분포이다.
- KL Divergence(Kullback-Leibler Divergence): p(y|x)와 p(y)가 얼마나 유사하거나 다른지에 대한 척도로, 특정 label이 높게 나온 conditional label distribution과 균등한 Marginal distribution일 때 가장 이상적인 Inception Score를 나타내게 됨.
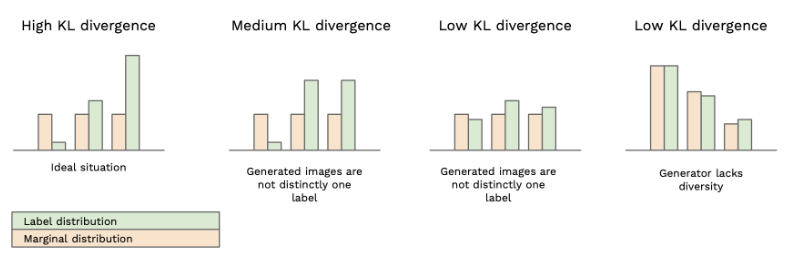
Inception Score는 가장 낮은 값은 1.0이고, 가장 높은 값은 분류 모델의 클래스의 개수이다. (Score가 높을 수록 좋은 모델)
한계점으로는 실제 샘플 대신 생성된 이미지를 사용해 계산하고, 클래스 당 하나의 이미지만 생성하게되면 다양성이 부족해도 p(y)가 균등 분포에 가깝게 나와 성능을 왜곡할 수 있다는 점이 있다.
FID (Frechet Inception Distance)
FID는 생성되는 이미지의 퀄리티 일관성을 유지하기 위해 이용되는 지표로, IS가 실제 데이터의 분포를 활용하지 않는 단점을 보완하여 실제 데이터와 생성된 데이터에서 얻은 feature의 평균과 공분산을 비교하는 방식이다.
FID가 낮을수록 이미지의 퀄리티가 더 좋아지며 이는 생성된 이미지와 실제 이미지 간의 유사도가 높다는 것을 의미한다. 가장 이상적인 모델은 FID가 0인 모델이며, 평균적으로 FID가 10 내외이면 성능이 좋은 모델이라고 판단할 수 있다.
한계점으로는 FID는 특정 생성 기법이 적용된 이미지에만 의미가 있는 평가 지표라는 점이다.

위 이미지에서, 1행 1열과 같이 노이즈가 들어간 이미지, 1행 3열과 같이 가려진 이미지에 대해서는 민감하게 반응하나 2행 1열 이미지(얼굴이 왜곡된 이미지)에 대해서는 FID가 낮게 올라가는데(실제로 사람 육안으로 보기에는 얼굴이 왜곡된 이미지가 더 이상함) 이를 통해 특정 이미지 생성 기법에만 민감하게 반응하는 지표라는 것을 알 수 있다.
6. GAN 활용 사례(Use Case)
Midjourney
2022년 7월경에 출시되었으며 올해 일러스트레이터, 웹툰 작가들 사이에서 뜨거운 감자가 된 AI 그림 서비스 중 하나다.
사용자가 원하는 그림에 대해 텍스트를 입력하면 이를 그림으로 변환시켜주는 서비스인데 디스코드를 통해 이용할 수 있다. (무료 평가버전은 현재 종료된 상태임)
https://www.midjourney.com/home/
Midjourney 하면 Midjourney를 통해 생성한 그림(아래 이미지)이 2022년 미국 콜로라도 미술대회에서 디지털 아트 부문 1위를 차지해서 기사화가 되었던 일이 생각나는데 최근의 생성형 AI를 이용한 AI 그림, AI 보이스 컨텐츠들은 이제는 실제와 거의 구별이 힘든 수준이다.

Real eye Opener
Meta(구 Facebook)의 Real eye opener는 눈을 감은 사진을 눈을 뜨고 있는 사진으로 만들어주는 기술이다. 결과를 생성하기 위해 예제 정보를 활용하는 조건부 GAN인 ExGAN을 통해 구현했다고 한다.

